SmoothQuant: Smoothing systematic outliers in LLMs for efficient quantization
Accurate and Efficient Post-Training Quantization for Large Language Models


Introduction
SmoothQuant is a method proposed by MIT HAN Labs to enable integer 8 bit weight and integer 8 bit activation quantisation while overcoming the quantization losses incurred during quantization process. This method is exclusively studied for LLMs.
SmoothQuant uses a special scaling method which migrates the quantization difficulty from activations to weights. This issue of quantization difficulty was first analysed by the LLM.int8() paper by Tim Dettmers. SmoothQuant provides a solution for this issue.

The SmoothQuant applies to all matrix multiplications (where the activations and weights are mat-mulled in int8 precision) for most of the LLMs including OPT, BLOOM, GLM, MT-NLG and the LLAMA family.
Where is weight and activation quantization required?
GPUs are computed rich, but they are bottle-necked by the memory. To solve the memory bottleneck, we came up with Quantization. Here we only need weight compression so that the weights can be fit into the memory of the GPUs (especially consumer GPUs). The computation can be done in FP16. So keeping the storage in integer 4 bit or 8 bit is fine, for compute we can dequantize the weights back to FP16 to perform GEMM matrix multiplications.
But in cases of Edge AI devices, we would have a performance bottleneck as well. So not only storing the weights in integers, but also computing matrix multiplications in integers over FP16 would be beneficial.
This is where SmoothQuant comes to play. SmoothQuant is a weight and activation quantization technique.
Not only the Edge AI devices, even in GPUs GEMM matrix multiplications of integers is faster than in FP16. Hence, by quantizing the weights and activations to 8bit or 4bit integers, we can reduce GPU memory requirements, in size and bandwidth, and accelerate compute-intensive operations. For example, INT8 quantization of weights and activations can halve the GPU memory storage and double the throughput of matrix multiplications when compared to FP16.
What are the challenges of weight and activation quantization in LLMs?
But this is challenging. This process is not as straight forward as in CNN architecture models. As mentioned by the LLM.int8() paper by Tim Dettmers, we know that as the LLM model size / C4 perplexity increases, we see the emergence of outlier features. The solution given by LLM.int8() paper is to use mixed precision decomposition.

8-bit Vector-wise Quantization
(1) Find vector-wise constants: C & C
2
3
1
cx
2
o
-1
3
-1
x
2
FIG
w
F16
w
(2) Quantize
(127/Cx) =
(127/cw) =
(3) Int8 Matmul
outl
x
-1 37 -1 8 0
Regular values
Outliers
W
P16
(4) Dequantize
Out* (C @C )
132 x w
127*127
Out
FP16
= Out
F16
16-bit Decomposition
(1) Decompose outliers (2) FP16 Matmul
45 1
: X 126
37 8
w
F16
X W = Out
FIG
FIG
F16
FIG
Figure 2: Schematic of LLM.int8(). Given 16-bit floating-point inputs Xf16 and weights Wf16, the
features and weights are decomposed into sub-matrices of large magnitude features and other values.
The outlier feature matrices are multiplied in 16-bit. All other values are multiplied in 8-bit. We
perform 8-bit vector-wise multiplication by scaling by row and column-wise absolute maximum of
Cm. and Cw and then quantizing the outputs to Int8. The Int32 matrix multiplication outputs Outt32
are dequantization by the outer product of the normalization constants CT @ Cu,. Finally, both outlier
and regular outputs are accumulated in 16-bit floating point outputs.")
This method includes keeping the non outliers in integer (low bit) precision while leaving the outlier feature vectors in the FP16 precision for computation. Though this solution works well in terms of accuracy, the overall performance in terms of throughput is not great because it is difficult to implement the decomposition efficiently on hardware. Therefore, we need to implement a pure quantized (weight and activation) implementation for the LLMs to get the desired throughput.
Activations are difficult to quantize in LLMs
As shown in the paper by Tim Dettmers (LLM.int8()), we understand that there is emergence of outliers in a certain feature channel of the transformer block which are important but difficult to quantize. The magnitude of the outliers in the activation are approximately in the range of 100x larger than the non-outlier values.
In the case of tensor wise quantization, these outliers dominate the maximum value in the quantization equation.

2N—1")
This causes low quantization bits or levels for non-outlier values and hence decreases the accuracy.
Weights are easy to quantize
Weight distribution is uniform and easy to quantize. As mentioned by previous papers such as llm.int8(), we can quantize the weights to int4 or int8 while retaining good accuracy.
Outliers persist in fixed channels:
Since outliers are present in certain channels, quantizing them per-tensor would not result in good accuracy since the variation of the magnitudes of activation values across channels is high. In such cases the per-channel quantization would be a better to use.
 per-tensor quantization
[Ixcol
per-channel quahi.
per-token quant.
(b) per-token + per-channel quantization
Figure 3: Definition of per-tensor, per-token, and per-
channel quantization. Per-tensor quantization is the most
efficient to implement. For vector-wise quantization to ef-
ficiently utilize the INT8 GEMM kernels, we can only use
scaling factors from the outer dimensions (i.e., token di-
mension T and out channel dimension Co) but not inner
dimension (i.e., in channel dimension CD.")
However, per-channel quantization of activation would not work well of hardware accelerators such as the GPUs. Though per-channel quantization could lower the quantization error, we cannot apply it for activations due to the difficulty of the dequantization.
The image below presents a normal linear forward with 1x2 input x and 2x2 weight w. The results y could be easily obtained by simple mathematics. In the middle image, we apply per-tensor quantization for activations and per-channel quantization for weights; the results after quantization that are denoted by y1 and y2, could be easily dequantized to the float results yfp1 and yfp2 by per channel scale 1.0/s1sx and 1.0/s2sx. However, after applying per-channel quantization for activation (right image), we could not dequantize the y1 and y2 to float results.

Therefore, all the previous works use the per token quantization for activation and per cannel quantization for weights techniques (llm.int8()) but they use mixed precision techniques. Though these techniques preserve the accuracy, but they are not faster in terms of throughput.
SmoothQuant
So SmoothQuant comes up with this solution that addresses the above problems. Instead of doing the per channel quantization of the activations, SmoothQuant proposes to scale the activation values (per channel) by a factor 's'. But if the activations are scaled by a variable 's', mathematically the matrix multiplication would not be correct. So to fix this, we scale the weights accordingly in the reverse direction as shown in the equation below.
W) Ⅱ xw")
Note that the scaling factor is different for each activation channel.
But scaling each input channel would cause additional compute right! To overcome this, the authors of the SmoothQuant paper propose to fuse the smoothing factor in the previous layer offline (as the output of the previous layer Is the input to the current layer). This method does not incur kernel call overhead.
The diagram below shows how scaling decreases the magnitude of the activations and adjusts the scaling in the weights. Overall both the activation and the weights would have a balanced maximum values that would be easier to quantize using the formula mentioned above.

Hard quuttize
Activation (SmoothQuant)
Easy to quantize
Weight (Original)
Very easy to quultize
Weight (SmoothQuant)
Harder but still easy to quantize
Figure 4: Magnitude of the input activations and weights of a linear layer in OPT-13B before and after SmoothQuant.
Observations: (1) there are a few channels in the original activation map whose magnitudes are very large (greater than 70);
(2) the variance in one activation channel is small; (3) the original weight distribution is flat and uniform. SmoothQuant
migrates the outlier channels from activation to weight. In the end, the outliers in the activation are greatly smoothed while
the weight is still pretty smooth and flat.")
SmoothQuant introduces a hyperparameter alpha as a smooth factor to calculate the conversion per-channel scale and balance the quantization difficulty of activation and weight.
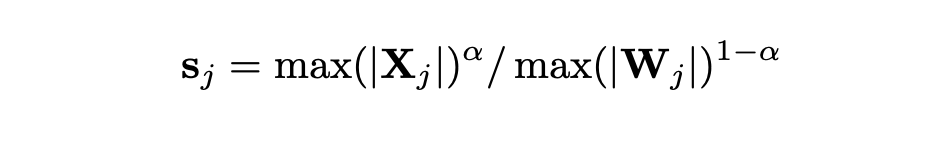
Note that here 'j' is the index of the input channels.
Migration strength of alpha
From experimentation, it was noticed that for models such ad OPT and BLOOM, alpha = 0.5 proved to show good results. Whereas if your model has significantly large outliers, a larger alpha value could be used to migrate the quantization difficulty to weights.

A suitable migration strength α (sweet spot) makes both activations and weights easy to quantize. If the α is too large, weights will be hard to quantize; if too small, activations will be hard to quantize.
Applying SmoothQuant to the transformer block
As shown in the diagram below, SmoothQuant is applied to only the compute intensive blocks of the transformer such as the Linear layers and the Batched mat mull layers.

<>
Experiment Results
With above configurations, SmoothQuant preserves the accuracy of existing language models across different scales when quantized to Int8. The below graph shows its performance on OPT models. Per-tensor (weight) and per-tensor static (activations) quantization configuration of SmoothQuant was used (named SmoothQuant-O3). Note that LLM.int8() uses mixed precision and suffers from inefficiency, unlike SmoothQuant.

W'8A8
ZeroQuant
• SmoothQuant-03
2.7B
6.7B
13B 30B
66B 175B
Model Size")
SmoothQuant can achieve W8A8 quantization of LLMs (e.g., OPT-175B) without degrading performance.

Outlier Suppression
53.4% 55.0%
SmoothQuant-O I
SmoothQuant-02
SmoothQuant-03
LAMBADA HellaSwag
74.7%
59.3%
0.0%
25.6%
0.0%*
26.0%
74.7%
59.2%
0.00%
25.8%
74.7%
59.2%
75.0%
59.0%
74.6%
58.9%
PIQA
79.7%
53.4%
51.7%
79.7%
52.5%
79.7%
79.2%
79.7%
WinoGrande
72.6%
50.3%
49.3%
72.1%
48.6%
71.2%
71.2%
71.2%
OpenB ookQA
34.0%
14.0%
17.8%
34.2%
16.6%
33.4%
33.0%
33.4%
RTE
59.9%
60.3%
58.1%
59.6%
59.9%
COPA
88.0%
87.0%
89.0%
88.0%
90.0%
Averaget
66.9%
35.5%
35.8%
66.7%
36.0%
66.5%
66.4%
66.8%
WikiTextJ
10.99
93080
84648
11.10
96151
11.11
11.14
11.17")
In the above table,
O1: per-tensor-weight & per-token-dynamic-activation quantization
O2: per-tensor-weight & per-tensor-dynamic-activation quantization
O3: per-tensor-weight & per-tensor-static-activation quantization
SmoothQuant can achieve faster inference compared to FP16 when integrated into PyTorch, while previous work LLM.int8() does not lead to acceleration (usually slower).

We also integrate SmoothQuant into the state-of-the-art serving framework FasterTransformer, achieving faster inference speed using only half the GPU numbers compared to FP16 (1 instead of 2 for OPT-66B, 4 instead of 8 for OPT-175B).

<>
References
GitHub repo: https://github.com/mit-han-lab/smoothquant/tree/main
Intel's SmoothQuant Variant: https://github.com/intel/neural-compressor/blob/master/docs/source/smooth_quant.md
Intel's SmoothQuant blog post: https://medium.com/intel-analytics-software/effective-post-training-quantization-for-large-language-models-with-enhanced-smoothquant-approach-93e9d104fb98
Video conference: EfficientML.ai Lecture 13 - Transformer and LLM (Part II) (MIT 6.5940, Fall 2023)